As assured, let’s deep dive into the knowings from my text-to-3D representative task. The objective was to surpass easy shapes and see if an AI representative might create intricate 3D designs utilizing Blender’s Python API.
The brief response: yes, however the architecture is whatever.
The Core Challenge: Reasoning vs. Syntax
Many LLMs can compose a basic Blender script for a cube. A “low poly city block”That needs preparation, model, and self-correction– jobs that press designs to their limitations. This isn’t simply a coding issue; it’s a thinking issue.
My Approach: A Hybrid Agent Architecture
I assumed that no single design might do it all. I developed a hybrid system that divides the work:
- A “Thinker” LLM (SOTA designs): Accountable for top-level thinking, preparing the actions, and producing preliminary code.
- A “Doer” LLM (Specialized Coder designs): Accountable for refining, debugging, and making sure syntactical accuracy of the code.
I checked 3 architectures on jobs of differing problem:
- Uniform SOTA: A big design doing whatever.
- Uniform Small: A little coder design doing whatever.
- Hybrid: The “Thinker” + “Doer” method.
The Results: 3 Key Takeaways
The information from the experiments was exceptionally clear.
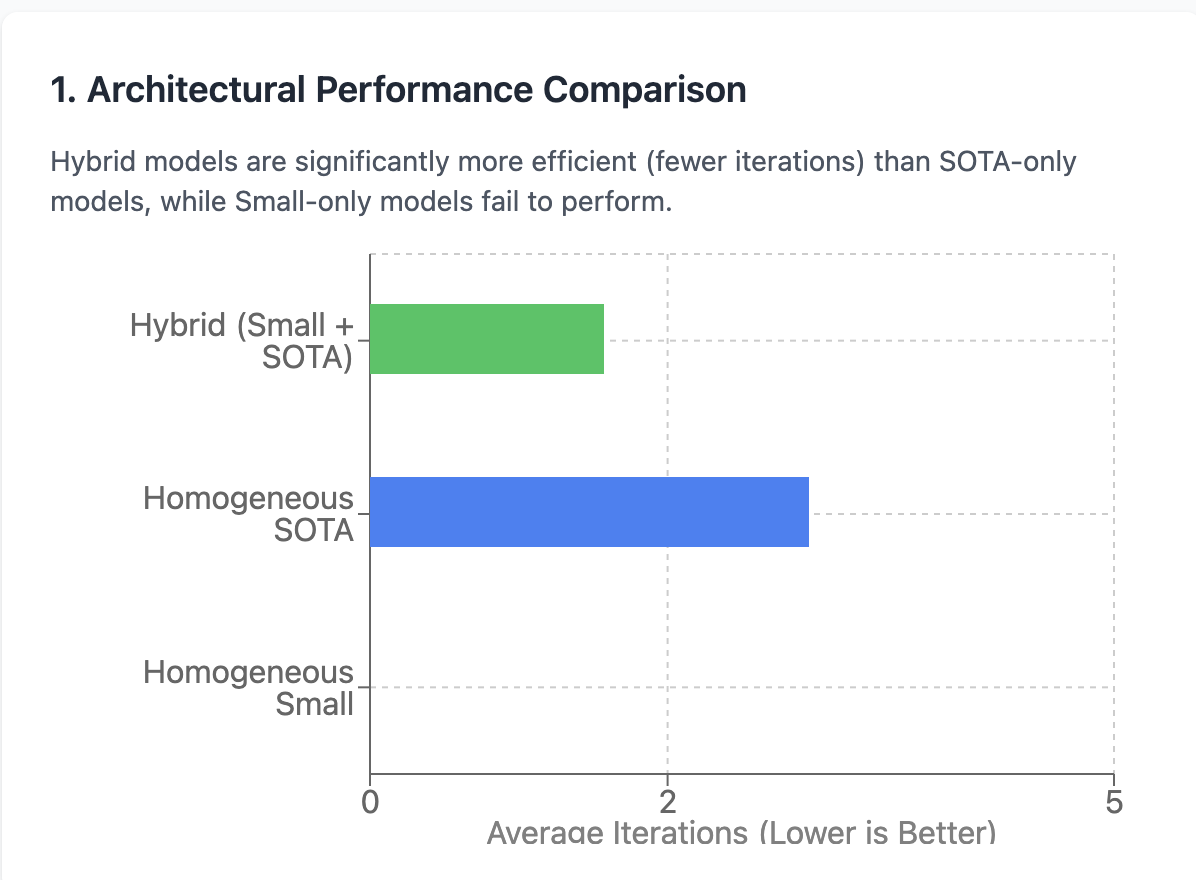
1. The Hybrid Model is the Undisputed Winner
Combining an effective thinking LLM with a specialized coder LLM was considerably more effective (less models) and dependable than utilizing a single SOTA design for whatever.
2. Uniform Small Models are a Trap
Utilizing just a little coder design for both thinking and syntax was a dish for catastrophe. This architecture stopped working 100% of the time, frequently getting stuck in limitless “tool loops” and never ever finishing the job.
3. Memory Had an Unexpected Impact.
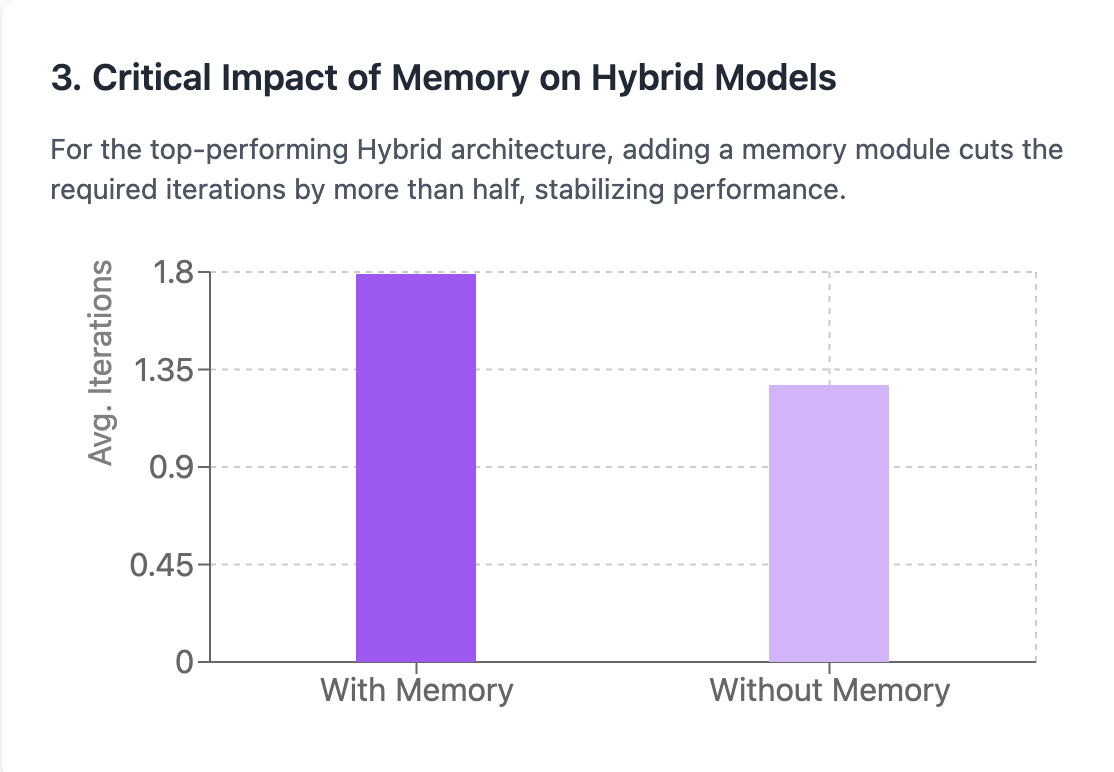
Contrary to my preliminary hypothesis, including a memory module in this setup in fact increased the typical variety of models. This recommends that the existing memory execution may be presenting overhead or triggering the representative to over-index on previous actions instead of enhancing performance. Fascinating issue that requires more examination.
Qualitative Insights: How the Models Behaved
- Design Quality: For visual appeal and imagination, the SOTA designs were unequaled. Gemini and Claude produced the most remarkable geometry.
- Tool Looping: Qwen had the greatest propensity to get stuck in loops, making it undependable as a standalone representative.
- Context Issues: GLM carried out fairly well however had a hard time to preserve structured output with a long context history.
Application Considerations
When constructing your own hybrid representative architecture, think about these aspects:
- Job Decomposition: Plainly different thinking jobs from execution jobs
- Design Selection: Select designs that master their particular domain (thinking vs. code generation)
- Mistake Handling: Develop robust loops detection and healing systems
The Big Picture
Structure reliable AI representatives isn’t about discovering one “god-tier” design. It’s about wise architecture. By making up specialized designs and providing memory, we can produce representatives that are much more capable than the amount of their parts.
This opens a new age of gen AI tools for intricate imaginative work. The future of AI representatives lies not in larger designs, however in much better orchestration of specialized designs collaborating.

AI Content Analysis
This content has been analyzed for AI generation:
- AI Probability: 0%
- Confidence:
- Last Checked: October 6, 2025